지금 몇 시야?
사용자가 “지금 몇 시야”라는 음성 명령어를 발화했을 때, 음성 명령어를 인식하고 음성으로 응답을 출력하는 시나리오입니다.
안내
수신한 텍스트 메시지를 통해 오디오 재생을 하기 위해, Player Queue를 구현해야 합니다. Player Queue는 Play 채널, Speak 채널, Alert 채널, 시보 채널로 구분되며, 자세한 설명은 [Kakao i Agent] Player Queue를 참고하시기 바랍니다.
- “지금 몇 시야?” 시나리오에서는 Speak 채널의 구현이 필요합니다.
Wake-up 1(음성)
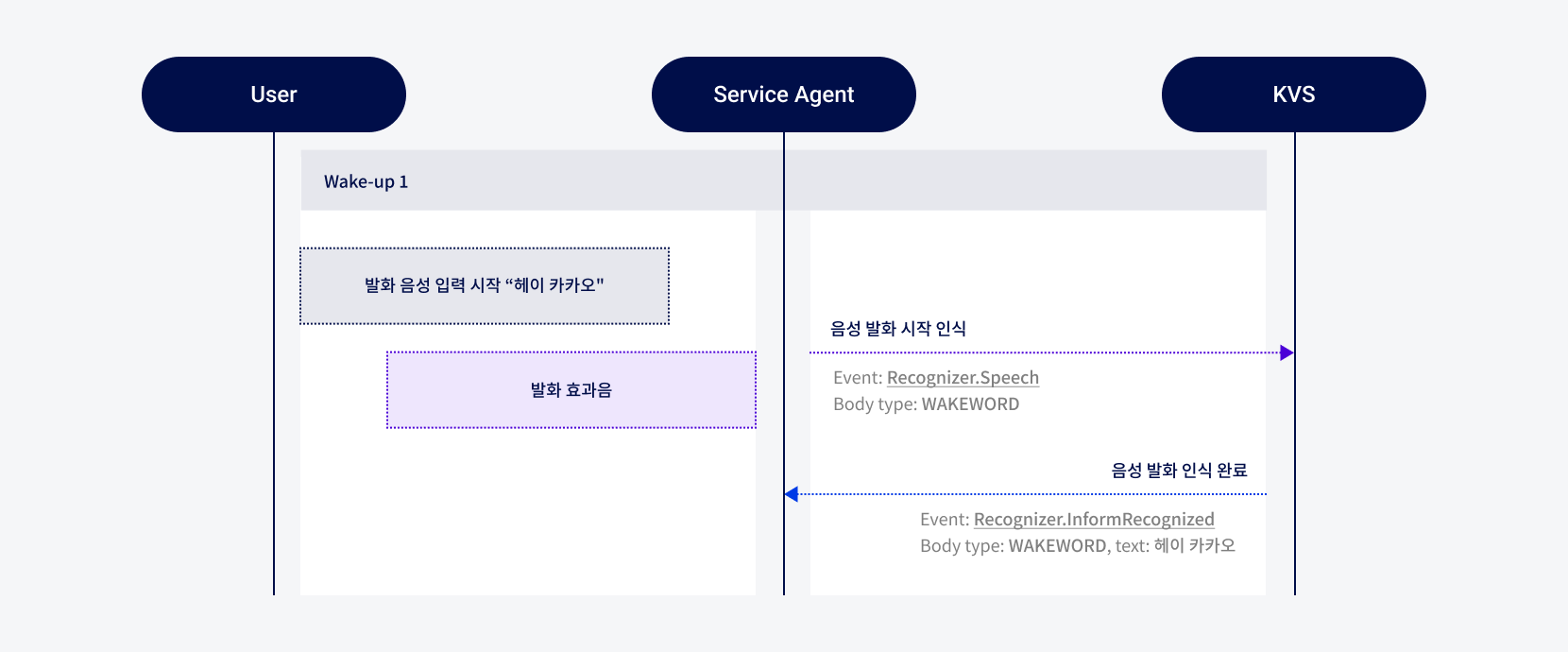 그림Wake-up 1(음성) 시나리오
그림Wake-up 1(음성) 시나리오
-
사용자가 Wake-up Word(호출 명령어)인 “헤이 카카오”를 발화합니다.
-
Service Agent는 발화 효과음 “띠링”과 함께 발화가 시작되었음을 인식하는 Recognizer.Speech Event와 인식된 음성 데이터를 KVS(Kakao i agent Virtual Service)에 전송합니다.
표Recognizer.Speech구분 설명 Interface Recognizer.Speech: Service Agent에서 발생한 사용자 발화를 KVS에 전달 메시지 타입: Event
인터페이스 타입: Recognizer
인터페이스: SpeechBody type으로 구성됨 type: WAKEWORD안내
Service Agent에서 발화 인식 기준이 미달되었지만 KVS에서 인식 기준을 충족했을 경우, Service Agent는 KVS로부터 전달받은 Recognizer.InformRecognized Instruction의 데이터를 기준으로 발화를 인식합니다. -
KVS는 발화가 인식 되었음을 알려주는 Recognizer.InformRecognized Instruction을 Service Agent에 전송합니다.
표Recognizer.InformRecognized구분 설명 Interface Recognizer.InformRecognized: KVS가 음성 인식 진행 중간/최종 결과를 Service Agent에 전달 메시지 타입: Instruction
인터페이스 타입: Recognizer
인터페이스: InformRecognizedBody type과 text로 구성됨 type: WAKEUP
text: 헤이 카카오
음성 명령
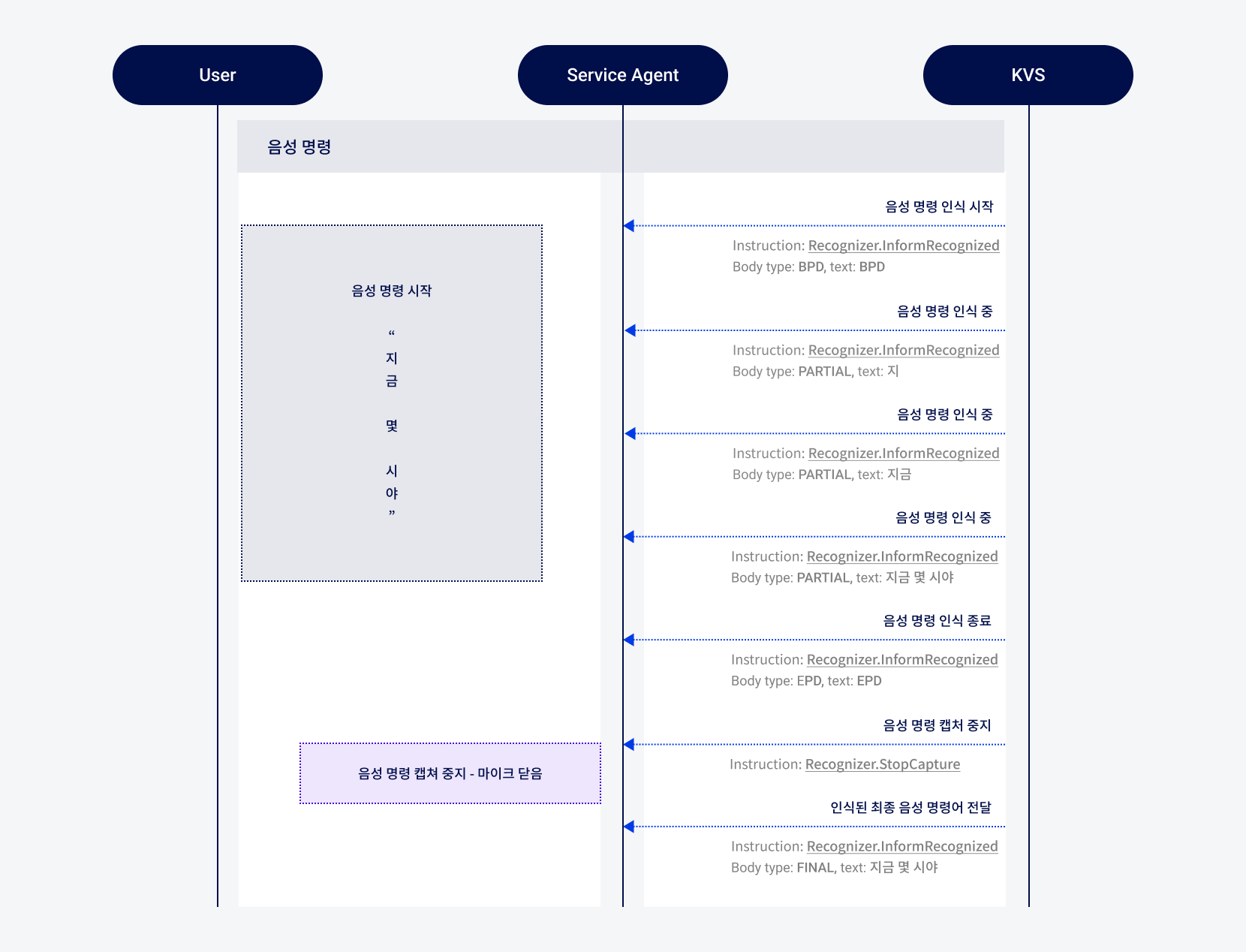 그림음성 명령 시나리오
그림음성 명령 시나리오
음성 명령 인식 시작
-
사용자가 Service Agent에 “지금 몇 시야?”라는 음성 명령을 합니다.
-
KVS가 음성 명령 시작을 인식하고, Recognizer.InformRecognized Instruction을 Service Agent에 전송합니다.
- Recognizer.InformRecognized Instruction은 음성 인식 진행 중간 결과와 최종 결과를 Service Agent에 전달해주는 인터페이스이며, 각 단계별 인식 결과를 전송할 때 type을 특정하여 전송합니다.
표Recognizer.InformRecognized
구분 설명 Interface Recognizer.InformRecognized: KVS가 음성 인식 진행 중간/최종 결과를 Service Agent에 전달 메시지 타입: Instruction
인터페이스 타입: Recognizer
인터페이스: InformRecognizedBody type과 text로 구성됨 type: BPD(인식 시작)
text:BPDtype: PARTIAL(인식 중)
text: "지!", "지금", "지금 몇 시야?"type: EPD(인식 종료)
text:EPD
안내
Recognizer.InformRecognized의 Body 타입에 사용되는 약자와 의미는 다음과 같습니다.
-BPD(Begin Point Detection): 사용자가 발화를 시작하는 것으로 판단
-PARTIAL(Partial Result) :사용자가 발화를 끝내기 전의 중간 인식 결과
-EPD(End Point Detection): 사용자가 발화를 종료한 것으로 판단
-FINAL(Final Result): 사용자가 발화한 음성의 최종 결과
음성 명령 캡처 중지
KVS가 전달받은 음성을 통해 완전한 명령어를 인식하면, Service Agent에 음성 캡처 중지를 요청하는 Recognizer.StopCapture Instruction을 전송합니다. Service Agent는 Recognizer.StopCapture Instruction을 전달받으면 즉시 마이크를 닫습니다.
표Recognizer.StopCapture| 구분 | 설명 |
|---|---|
| Interface | Recognizer.StopCapture: KVS가 사용자의 의도를 파악했거나 명령어 인식을 종료할 때 사용자의 음성 캡처를 중지하도록 Service Agent에 지시 |
| 메시지 타입: Instruction 인터페이스 타입: Recognizer 인터페이스: StopCapture |
음성 명령 인식 완료
KVS는 최종 인식 결과를 Recognizer.InformRecognized(type: FINAL) Instruction을 통해 Service Agent에 전달합니다.
| 구분 | 설명 |
|---|---|
| Interface | Recognizer.InformRecognized: KVS가 음성 인식 진행 중간 결과와 최종 결과를 Service Agent에 전달하는 Instruction |
| 메시지 타입: Instruction 인터페이스 타입: Recognizer 인터페이스: InformRecognized |
|
| Body | type과 text로 구성됨 |
type: FINAL(인식 완료)text: 지금 몇 시야 |
음성 답변
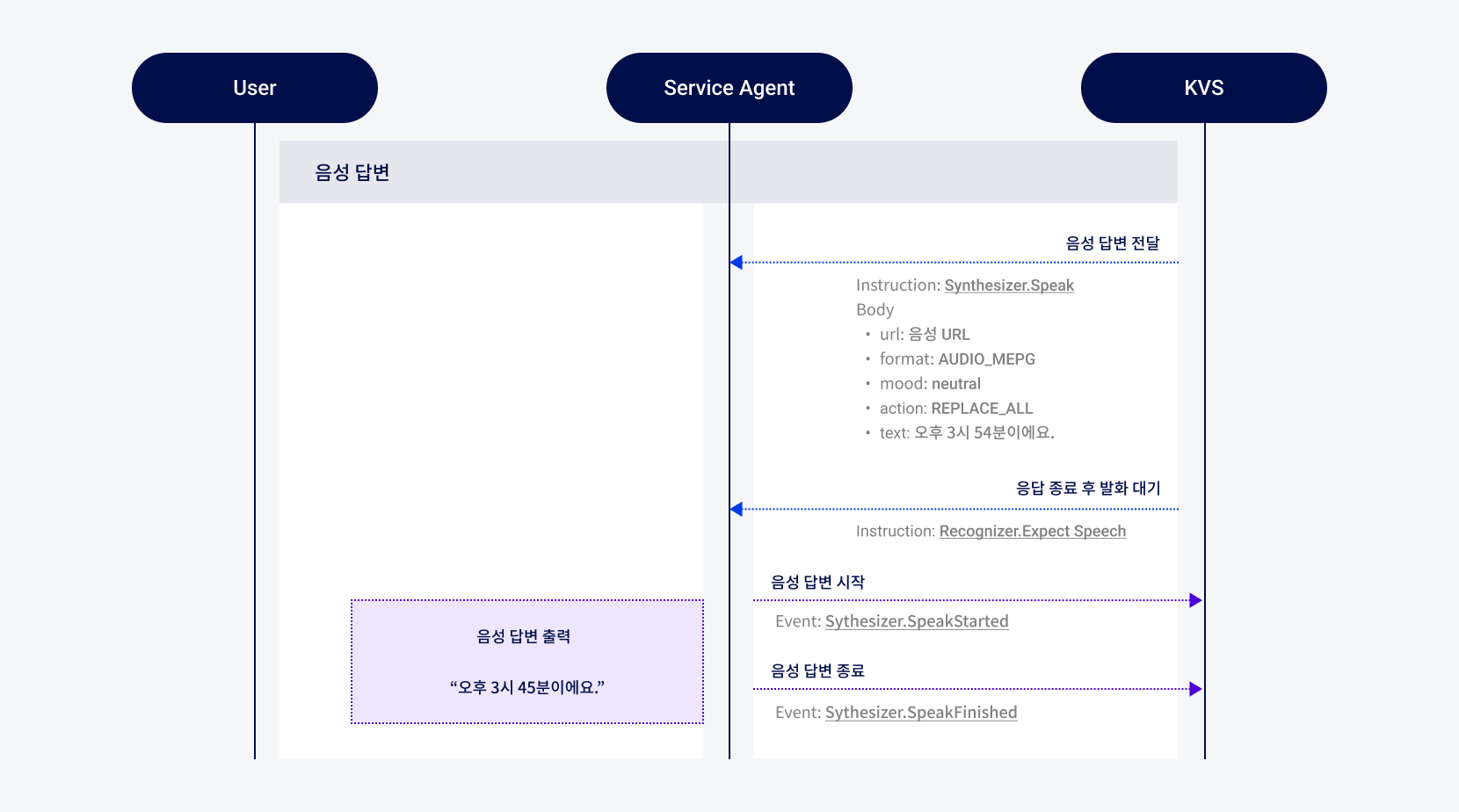 그림음성 답변 시나리오
그림음성 답변 시나리오
-
KVS는 Synthesizer.Speak Instruction과 데이터를 Service Agent에 전송합니다.
표Synthesizer.Speak구분 설명 Interface Synthesizer.Speak: Service Agent에 음성 응답이 필요할 때마다 KVS가 Service Agent에 전송 메시지 타입: Instruction
인터페이스 타입: Synthesizer
인터페이스: SpeakBody url, format, mood, text로 구성됨 url: 음성 URL
format:AUDIO_MPEG
mood:Neutral
text: 오후 3시 54분이에요. -
사용자의 추가 발화에 대기하기 위해 KVS는 Recognizer.ExpectSpeech Instruction을 Service Agent에 전송합니다.
- Service Agent는 Recognizer.ExpectSpeech Instruction을 수신하면, 모든 응답을 종료한 후 다시 발화 대기 상태로 전환합니다.
구분 설명 Interface Recognizer.ExpectSpeech: KVS가 사용자에게 추가적인 발화를 원할 때, 마이크를 열고 사용자의 발화를 기다리도록 Service Agent에 지시 메시지 타입: Instruction
인터페이스 타입: Recognizer
인터페이스: ExportSpeech -
Service Agent가 음성 답변(“오후 3시 54분 이에요”)을 재생하고, Synthesizer.SpeakStarted Event를 KVS에 전송합니다.
표Synthesizer.SpeakStarted구분 설명 Interface Synthesizer.SpeakStarted: Service Agent가 Speak Instruction을 처리하고 합성된 음성의 재생을 시작한 후에 KVS에 전송 메시지 타입: Event
인터페이스 타입: Synthesizer
인터페이스: SpeakStarted -
음성 응답이 완전히 종료되면, Service Agent는 KVS에 Synthesizer.SpeakFinished Event를 전송합니다.
표Synthesizer.SpeakFinished구분 설명 Interface Synthesizer.SpeakFinished: Service Agent가 Speak Instruction을 처리하고 합성된 음성의 재생을 마친 후에 KVS에 전송 메시지 타입: Event
인터페이스 타입: Synthesizer
인터페이스: SpeakFinished
안내
수신된 음성 응답은 Speak 채널의 Player Queue에 추가되어 순차적으로 출력됩니다.
Wake-up 2
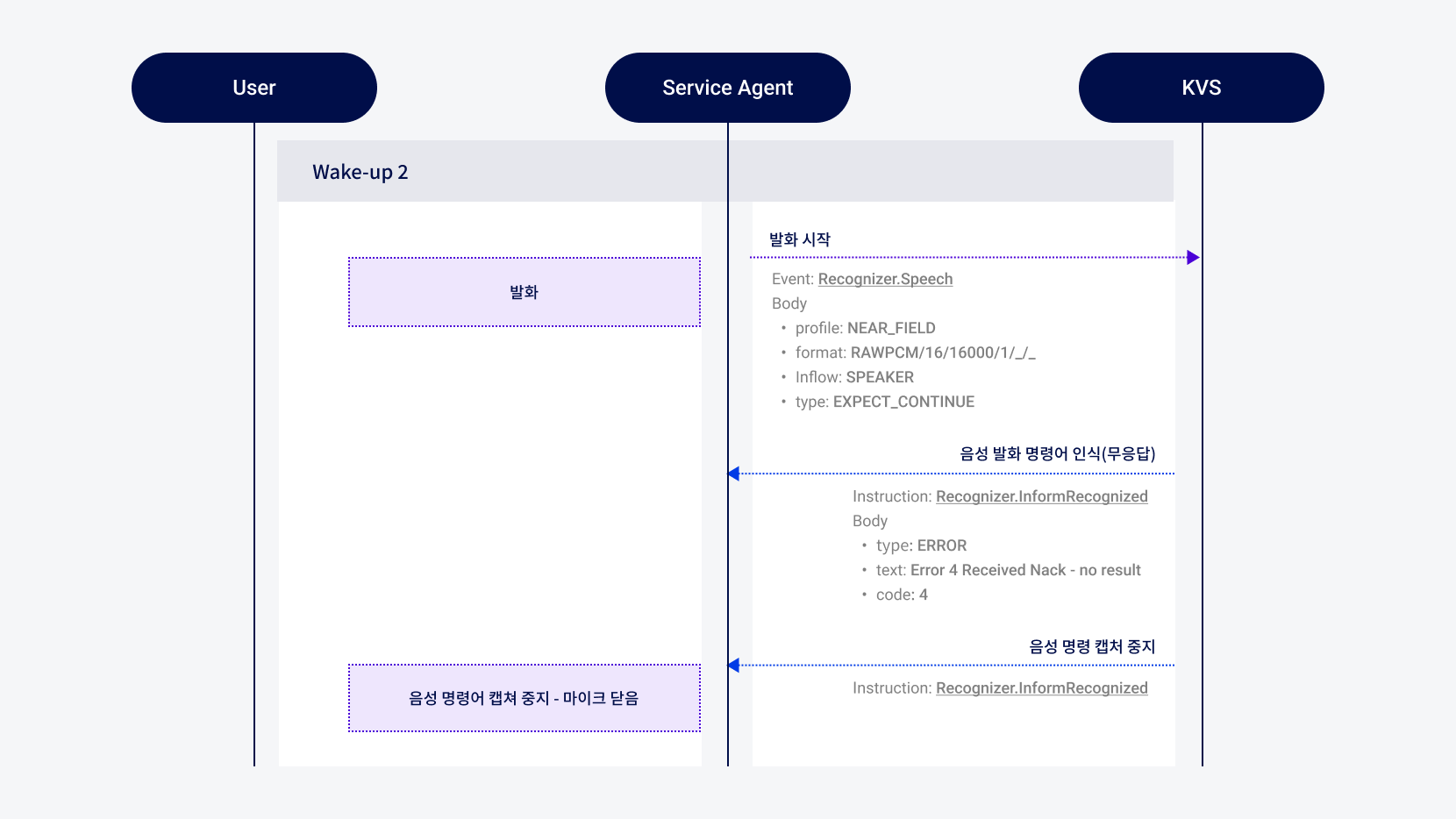 그림Wake-up 2 시나리오
그림Wake-up 2 시나리오
-
모든 응답이 종료되면 Service Agent는 발화 효과음(“띠링”)과 함께 Recognizer.Speech Event를 KVS에 전송합니다.
표Recognizer.Speech구분 설명 Interface Recognizer.Speech: Service Agent에서 발생한 사용자 발화를 KVS에 전달 메시지 타입: Event
인터페이스 타입: Recognizer
인터페이스: SpeechBody field, format, inflow, type으로 구성됨 field: Near_Field
format:RAWPCM/16/16000/1_/_
inflow:Speaker
type:EXPECT_CONTINUE안내
발화 상태로 전환된 이후에는 사용자의 응답 여부 및 Service Agent의 발화 이전 상태에 따라 Service Agent의 동작이 달라집니다. -
KVS는 Recognizer.InformRecognized Instruction을 Service Agent에 전송합니다.
- 이 시나리오는 사용자의 추가 발화가 없는 경우이므로 type에
ERROR가 전달됩니다.
구분 설명 Interface Recognizer.InformRecognized: KVS가 음성 인식 진행 중간 결과와 최종 결과를 Service Agent에 전달하는 Instruction 메시지 타입: Instruction
인터페이스 타입: Recognizer
인터페이스: InformRecognizedBody type, text, code로 구성됨 type: ERROR
text:Error 4 Received Nack - no result
code:4 - 이 시나리오는 사용자의 추가 발화가 없는 경우이므로 type에
-
추가 발화가 없으므로, KVS는 음성 명령 인식을 중단하는 Recognizer.StopCapture Instruction을 Service Agent에 전송합니다.
- Service Agent는 Recognizer.StopCapture Instruction을 수신하면 즉시 마이크를 닫습니다.
구분 설명 Interface Recognizer.StopCapture: KVS가 사용자의 의도를 파악했거나 명령어 인식을 종료할 때 사용자의 음성 캡처를 중지하도록 Service Agent에 지시 메시지 타입: Instruction
인터페이스 타입: Recognizer
인터페이스: StopCapture